画像生成AIでコンテ画を描いてみる
私は広告映像ディレクターなので、絵コンテというものを描きます。
こんな絵が何カットも並んでいるものです。

これは「ビジネス街を颯爽と歩く女性」っていうカットです。
ケータイとかITとかドリンクとかシャンプーとかのCMでよくある絵ですね。
私はこの絵コンテで、どんな映像になるかをクライアントにご理解していただき、どんな絵を撮って欲しいかカメラマンに説明します。
あれ?それって画像生成AIの得意ジャンルなんじゃね?っていうのが今回のテーマです。
では、私の雑な絵をAIで写真化してみましょう。
◆SeaArt
前回のBlogまではStable Diffusionだったのですが、今回はSeaArtというAIを使います。
実はこの2つは元は同じなんじゃないかと思っています。
SeaArtはすごくイージーで日本語でプロンプトが書けて機能も充実していて、しかもいまのところ無料です。
でもなんか怪しい。中国製のようで、漢字がときどき中国語です。商用利用はOKではないようです。サンプルにエロい画像多いです。
とはいえ便利で高性能なので、今回はこれで行きます。
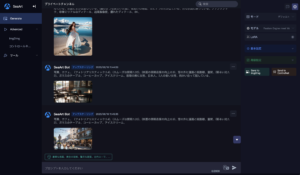
インターフェースはこんな感じです。
◆Img2Imgで生成
左の方に” Generate” “Advanced”ってあってその” Advanced”の三角をクリックすると中に” Img2Img”ってあるので、それを選んで元絵をドラッグ&ドロップでホイッ!
こんなふうに元絵が設定されます。
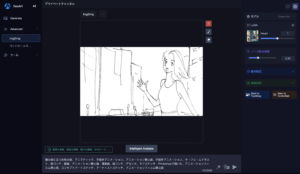
そうすると、下のウインドウにプロンプトを入れろと言ってきます。
ちなみに画像を用意しなくてもプロンプトさえ入れれば”Tx2Img”で言葉から画像を生成できます。”Text to Image”「言葉から画像」です。そっちが王道なのですが、今回は構図とか姿勢とか背景とか絵で指定したかったので” Img2Img”「画像から画像」でやっています。
で、プロンプト。まずこんな風に入れました。
![]()
「写真、(フォトリアリスティック:1.4)、(ハイパーリアリスティック:1.4)、(cinematic:1.5)、20代女性、日本人、歩いている、白いワンピース、黒髪、カメラに手を振る、風で髪がなびく、ソロ、(美しく繊細な顔)、高品質な目、大都会、ガラス張りのビル、青空、夏の日差し、レンズフレア、canon EF35mm, f:5.6,」
最初の方の「写真」とか「(フォトリアリスティック:1.4)」とか結構重要なようで、要するにクォリティの高い写真にしろよとAIに言ってます。品質に関するプロンプトはこれがベストかどうかわかりません。他の人がやってるのから良さげなのを選んでコピペしました。
そしたらこんなのが上がってきた。

4枚ワンセットで上がってきます。
いや、なんか違うだろ。
部屋ん中じゃないよ。服透けてなくていいし。なにかとセクシーにしたがるのがSeaArtのよいところでもあり悪いところでもあります。しかも顔崩れてるじゃん。いや、君はもっとできるはずだ。
◆試行錯誤
というわけで、プロンプトやディテールの設定を変えて再生成。
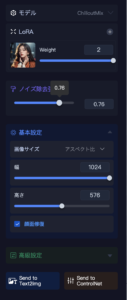
再生成するときにいろいろ変更すると面白いのが右上の”モデル”と”LoRA”です。ここを変更することで相当絵が変わります。”モデル“はどんな感じの絵にするかっていうコマンドで、”LoRA”はどんなキャラクターにするかっていうことだと思って今のところ使っていますが、違うかもしれません。”モデル”と”LoRA”は相性があるようで、外すと酷いことになります。
ちなみに”LoRA”は”Low-Rank Adaptation”の略だそうです。
私はこの赤い服の女性の”LoRA”が気に入っているので、”モデル“を変えつつ”LoRA”はこれで押し通します。
で、いろいろ試行錯誤します。今回は18回やり直しました。
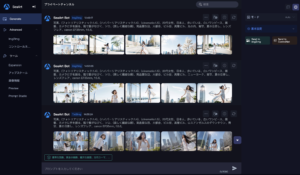
部屋の中になってしまったのは「ガラス張りのビル」っていうプロンプトがいけなかったようです。ビルの中だと受け止められてしまったわけですね。代わりに「東京」とか「ニューヨーク」とか入れてみて「ロスアンゼルスのダウンタウン」っていうのが一番イメージに近いビル街の背景になりました。
で、できたのがこちら。

かなりいいんですが、背景のビルが絵っぽいな。
というわけで、ビルが得意そうな”モデル“を探して背景を再生成。
そのあとPhotoshopを使って人物と背景を合成しました。
◆完成!
結果、この絵が、
こう完成しました。

まあ、かなりカッコいいです。
悪くない。
ですが、イメージしてたのとは違います。イメージとしてはビルがもうちょっと近くてビル街の道路を歩いてる感じだったんだけど。で、画面右から左に歩いて欲しいんだが。
相当クォリティは高いですが、狙い通りではありません。
ここまで持ってくるのに3時間くらいかかりました。
1カットで。
これコンテにすることを考えると、例えば15秒CMでも5〜10カット必要なわけですが、問題は服装が毎カット変わってしまうことなんですよね。顔はわりと似てるんだけど、服のデザインが毎回変わる。背景も毎回微妙に変わる。
あと相変わらずAIは指の表現は苦手ですね。
狙った通りの画像を生成するには、まだ私もAIも進化が必要なようです。
でも私はともかく、AI進化激速いからな。今年の秋頃には物凄いことになっていそうな気がします。